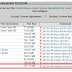
TDD 법칙 세 가지
- 첫째 법칙: 실패하는 단위 테스트를 작성할 때까지 실제 코드를 작성하지 않는다.
- 둘째 법칙: 컴파일은 실패하지 않으면서 실행이 실패하는 정도로만 단위 테스트를 작성한다.
- 셋째 법칙: 현재 실패하는 테스트를 통과할 정도로만 실제 코드를 작성한다.
깨끗한 테스트 코드 유지하기
지저분한 테스트 코드라도 있는 것이 좋을 것이라고 판단하기 쉬우나 사실은 테스틑를 안하는 것 보다 더 나쁘다.
실제코드가 진화하면 테스트 코드도 변해야 한다. 그런데 테스트 코드가 복잡하면 실제 코드를 짜는 시간보다 테스트 케이스를 추가하는 시간이 더걸리기 십상이다.
새 버전 출시할 때 마다 팀이 테스트 케이스를 유지하고 보수하는 비용도 늘어 테스트 코드가 점차 개발자 사이에서 가장 큰 불만으로 자리 잡는다.
하지만 테스트 슈트가 없으면 개발자는 자신이 수정한 코드가 제대로 도는지 확인할 방법이 없다. 테스트 슈트가 없으면 시스템 이쪽을 수정해도 저쪽이 안전하다는 사실을 검증하지 못한다. 그래서 결합율이 높아지기 시작한다.
변경하면 듣곱다 해가 크다 생각해 더 이상 코드를 정리하지 않고, 그러면 코드가 망가지기 시작한다. 결국 테스트 슈트도 없고 얼기설기 뒤섞인 코드에 좌절한 고객과 테스트에 쏟아 부은 노력이 허라였다는 살망감만 남는다.
테스트 코드는 실제 코드 못지 않게 중요하다.
테스트는 유연성, 유지보수성, 재사용성을 제공한다.
테스트 코드를 깨끗하게 유지하지 않으면 결국 잃어버린다. 그리고 테스트 케이스가 없으면 실제 코드를 유연하게 만드는 버팀목도 사라진다.
코드에 유연성, 유지보수성, 재사용성을 제공하는 버팀목이 바로 단위 테스트다. 이유는 단순하다. 테스트 케이스가 있으면 변경이 두렵지 않다.
테스트 코드가 없으면 설계를 아무리 잘 해도 모든 변경이 잠정적인 버그다.
실제 코드를 점검하는 자동화된 단위 테스트 슈트는 설계와 아키텍처를 최대한 깨끗하게 보존하는 열쇠다. 테스트는 유연성, 유지보수성, 재사용성을 제공한다.
깨끗한 테스트 코드
깨끗한 테스트 코드를 만들려면 가독성이 필요하다.
가독성을 높이려면 명료성, 단순성, 풍부한 표현력이 필요하다.
테스트 코드는 최소의 표현으로 많은 것을 나타내야 한다.
도메인에 특화된 테스트 언어
public void testGetPageHierarchyAsXml() throws Exception {
makePages("pageOne", "pageOne.ChiildOne", "PageTwo");
submitRequest("root", "type:pages");
assertResponseIsXml();
assertResponseContains("<name>PageOne</name>", "<name>PageTwo</name>", "<name>ChildOne</name>");)
}
public void testSymbolicLinkAreNotInXmlPageHierachy() throws Exception {
WikiPage page = makePage("PageOne");
makePages("PageOne.ChioldOne", "PageTow");
addLinkTo(page, "PageTwo", "SymPage");
submitRequest("root", "type:pages");
assertResponseIsXml();
assertResponseContains("<name>PageOne</name>", "<name>PageTwo</name>", "<name>ChildOne</name>");)
assertResponseDoesNotContain("SymPage");
}
public void testGetDataAXml() throws Exception {
makePageWithContent("TestPageOne", "test page");
submitRequest("TestPageOne", "type:data");
assertREsponseIsXML();
assertResponseContains("test page", "<test");
}
이 코드는 도메인에 특화된 언어로 테스트 코드를 구현하는 기법을 보여준다.
흔히 쓰는 시스템 조작 API 를 사용하는 대신 API 위에 함수와 유틸리티를 규현한 후 그 함수와 유틸리티를 사용하므로 테스트 코드를 짜기도 읽기도 쉬워진다.
이렇게 구현한 함수와 유틸리티를 사용하므로 테스트 코드를 짜기도 읽기도 쉬워진다.
이렇게 구현한 함수와 유틸리티는 테스트 코드에서 사용하는 특수 API가 된다. 즉, 테스트를 구현하는 당사자와 나중에 테스트를 일겅볼 독자를 도와주는 테스트 언어가 된다.
이중 표준
테스트 API 코드에 적용하는 표준은 실제 코드에 적용하는 표준과 확실히 다르다.
단순하고 간결하고 표현력이 풍부해야 하지만 실제 코드만큼 효율적일 필요는 없다.
실제 환경이 아니라 테스트 환경에서 돌아가는 코드이기 때문이다. 실제 환경과 테스트 환경은 요구사항이 판이하게 다르다.
아래 코드는 온도가 급격하게 떨어지면 경보 온풍기 송푸기 가 모두 가동되는지 확인하는 코드이다.
@Test
public void turnOnLoTempAlarmAtThreshold() throws Exception {
hw.setTemp(WAY_TOO_COLD);
controller.tic();
assertTrue(hw.heaterState());
assertTrue(hw.blowerState());
assertFalse(hw.collerState());
assertFalse(hw.hiTempAlarm());
assertTrue(hw.loTempAlarm());
}
위 코드는 가독성이 좋지 않다, 아래와 같이 변경하면 가독성이 높아진다.
@Test
public void turnOnLoTempAlarmAtThreshold() throws Exception {
wayTooColde();
assertEquals("HBchL", hw.getState());
}
wayTooColde 함수를 만들어서 tic 함수 를 숨겼다.
“HBchL” 라는 문자열을 만들어 새로운 상태값을 만들었다. (물론 그릇된 정보를 피하라 규칙 위반에 가깝지만 여기에서는 적절해보인다.)
문자는 {heater, blower, cooler, hi-temp-alarm, lo-temp-alarm} 순서이고 대문자는 켜짐 소문자는 꺼짐이다.
이렇게 만들면 아래와 같이 테스트 코드를 확장할 수도 있다
@Test
public void turnOnCoolerAndBlowerIfTooHot() throws Exception {
tooHot();
assertEquals("hBChl", hw.getState());
}
@Test
public void turnOnHeaterAndBlowerIfTooCold() throws Exception {
tooHot();
assertEquals("HBchl", hw.getState());
}
getState 함수를 살펴보면 아래와 같이 작성했다.
public String getState() {
String state = "";
state += heater ? "H" : "h";
state += blower ? "B" : "b";
state += cooler ? "C" : "c";
state += hiTempAlarm ? "H" : "h";
state += loTempAlarm ? "L" : "l";
retyrb state;
}
StriugBufer는 보기에 흉하다. StriugBufer 를 안 써서 치르는 대가가 미미하다. 하지만 이 프로그램은 임베디드 시스템이기 때문에 자원과 메모리가 제한적일 가능성이 높다. 하지만 테스트 환경의 자원은 제한적이지 않다
이것이 이중 표준의 본질이다. 실제 환경에서는 절대로 안 되지만 테스트 환경에서는 전혀 문제가 없는 방식이 있다. 대게 메모리나 CPU 효율과 관련 있는 경우다. 코드의 깨끗함과는 무관하다.
테스트 당 assert 는 하나
JUnit 으로 테스트 코드를 짤 때는 함수마다 assert 문을 단 하나만 사용해야 한다고 주장하는 학파가 있따. 가혹한 규칙이라 여길지도 모르지만 확실히 장점은 있따. assert 문이 단 하나인 함수는 결론이 하나라서 코드를 이해하기 쉽고 빠르다.
하지만 출력이 xml 인 경우 assert 문과 특정 문자열 포함한다는 assert 문을 하나로 병합하는 방식이 불합리해 보인다.
public void testGetPageHierarchyAsXml() throws Exception {
makePages("pageOne", "pageOne.ChiildOne", "PageTwo");
submitRequest("root", "type:pages");
assertResponseIsXml();
assertResponseContains("<name>PageOne</name>", "<name>PageTwo</name>", "<name>ChildOne</name>");)
}
public void testGetPageHierachAsXml() throws Exception {
givenPages("pageOne", "pageOne.ChiildOne", "PageTwo");
whenRequestIsIssued("root", "type:pages");
assertResponseIsXml();
}
public void testGetPageHierachyHasRightTags() throws Exception {
givenPages("pageOne", "pageOne.ChiildOne", "PageTwo");
whenRequestIsIssued("root", "type:pages");
assertResponseContains("<name>PageOne</name>", "<name>PageTwo</name>", "<name>ChildOne</name>");)
}
바꾸면서 given-when-then 이라는 관례를 사용했다 그러면 읽기가 쉬워진다.
불행하게도 위에서 보듯이 테스트를 분리하면 중복되는 코드가 많아진다.
TEMPLATE MTEHOD 패턴을 사용하면 중복을 제거할 수 있다.
given/when 부분을 부모 클래스에 두고 then 부분을 자식 클래스에 두면 된다. 아니면 완전히 독자적인 테스트 클래스를 만들어 @before 함수에 given/when 부분을 넣고 @Test 부분에 then 을 넣어도 된다.
이것 저것 감안해보면 assert 문을 여러개 사용하는 편이 좋다고 생각한다.
단일 assert 문 이라는 규칙은 훌륭한 지침이라 생각한다. 하지만 때로는 주저 없이 함수 하나에 여러 assert 문을 넣기도 한다. 단지 assert 문 개수를 최대한 줄여야 좋다고 생각한다.
테스트 당 개념은 하나
어쩌면 테스트 함수마다 한 개념만 테스트하라는 규칙이 더 낫다. 이것저것 잡다한 개념을 연속으로 테스트 하는 긴 함수를 피한다.
아래 코드는 여러 개념을 하나의 테스트로 진행하기 때문에 좋지 않다.
public void testAddMonth() {
SerialDate d1 = SeialDate.createInstance(31, 5, 2004);
SerialDate d2 = SerialDate.addMonths(1, d1);
assertEquals(30, d2.getDayOfMonth());
assertEquals(6, d2.getMonth());
assertEquals(2004, d2.getYYYY());
SerialDate d3 = SerialDate.addMonths(2, d1);
assertEquals(31, d3.getDayOfMonth());
assertEquals(7, d3.getMonth());
assertEquals(2004, d3.getYYYY());
SerialDate d4 = SerialDate.addMonths(1, SerialDate.addMonths(1, d1));
assertEquals(30, d4.getDayOfMonth());
assertEquals(7, d4.getMonth());
assertEquals(2004, d4.getYYYY());
}
F.I.R.S.T
깨끗한 테스트는 다음 다섯 가지 규칙을 따르게 된다.
빠르게 (First): 테스트는 빨라야 하낟.
독립적으로 (Independent): 각 테스트는 서로 의존하면 안 된다.
반복가능하게 (Repeateable): 테스트는 어떤 환경에서도 반복 가능해야 한다.
자가검증하는 (Self-Validating): 테스트는 부울 값으로 결과를 내야 한다.
적시에 (Timely): 테스트는 적시에 작성해야 한다.
결론
이 장은 주제를 수박 겉핡기 정로도만 훝었따. 사실상 꺠긋한 테스트 코드 라는 주제는 책 한권을 할애해도 모자랄 주제다. 테스트 코드는 실제 코드만큼이나 프로젝트 건강에 중요하다. 어쩌면 실제 코드보다 더 중요할지도 모르겠다. 테스트 코드는 실제 코드의 유연성, 유지보수성, 재사용성을 보존하고 강화하기 떄문이다. 그러므로 테스트 코드는 지속저긍로 깨끗하게 관리하자. 표현력을 높이고 간결하게 정리하자. 테스트 API 구현해 도메인 특화 언어를 만들자 그러면 그만큼 테스트 코드를 짜기가 쉬워진다. 테스트 코드가 방치되어 망가지면 실제 코드도 망가진다. 테스트 코드를 깨끗하게 유지하자.